High Performance Computing
Back in the day, the machines used for high performance computing were known as "supercomputers" or big standalone machines with specialized hardware–very different from what you would find in home and office computers.
Nowadays, however, the majority of supercomputers are instead computer clusters (or just "clusters" for short) --- collections of relatively low-cost standalone computers that are networked together. These inter-connected computers are endowed with software to coordinate programs on (or across) those computers, and they can therefore work together to perform computationally intensive tasks.
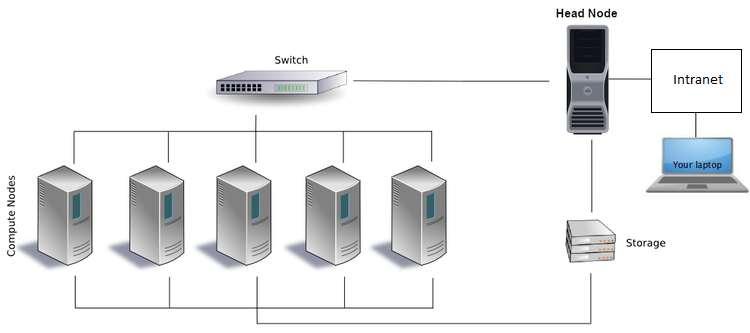
Each computer in the cluster is called a node (the term "node" comes from graph theory), and we commonly talk about two types of nodes: head node and compute nodes.
-
Head Node - The head node is the computer where we land when we log in to the cluster. This is where we edit scripts, compile code, and submit jobs to the scheduler. The head nodes are shared with other users and jobs should not be run on the head nodes themselves.
-
Compute Node - The compute nodes are the computers where jobs should be run. In order to run jobs on the compute nodes we must go through the job scheduler. By submitting jobs to the job scheduler, the jobs will automatically be run on the compute nodes once the requested resources are available.
A basic structure can be understood by the following diagram:-
1. What is a cluster?
A cluster consists of a large number of interconnected machines.
Each machine is very much like your own desktop computer, except it’s much more powerful. Like your desktop computer, each machine (often referred to as node) has a CPU, some memory, and a hard disk. The nodes running your programs are usually called compute nodes.
To turn the nodes into a cluster we need three more ingredients: a network, data storage, and a queue manager. In section we’ll discuss these components in a bit more detail to give you an understanding of how a cluster works.
1.1. Network
Nodes in the cluster connect to a high-performance network. The network allows programs running on different nodes to “talk” to each other.
1.2. Storage
The process is data intensive so we can’t just use a single hard disk as you would in your own computer. Instead, we buy several dedicated hard disks and use a file system that can manage files across these disks. The storage might be divided into partitions, and presented to the user in different locations on their path.
1.3. Queue manager
In theory, any user would be able to log in to any node and run a program, which may consume the resources of the entire node. This could cause other users’ programs on the same node to crash. Alternatively, one user could start thousands of runs of a program on different nodes, consuming the resources of the entire cluster for an unknown duration of time. In short, it would be impossible to share the HPC without a system to handle requests. To solve this problem we need a queue manager, which is a software that manages the requests for resources in a fair way. Like at the supermarket or an office, you stand in the queue and wait until it’s your turn. On the cluster, you submit jobs to the queue and your jobs will run on some node chosen by the queue manager, once resources are available.
The queue manager also allows you to specify certain requirements for your program to run. For example, your program may need to run on a node with a lot of memory. If you specify this when submitting your job, the queue manager will make sure to run the job on a node with at least that amount of memory available.
At IITJ we use a queue manager called Slurm: to run your programs on the HPC, you’ll be interacting a lot with Slurm.
1.4. Things to remember…
A few things that you should keep in mind when using the cluster:
In the coming sections you will learn how to connect to the cluster so that you can start submitting jobs.
-
The nodes in a cluster are set up so that they’re all (more or less) identical. Software that is available on one node will also be available on all other nodes and you can access your files in the same way on all nodes. When the queue manager runs your job on a node, it more or less corresponds to you logging in to the node and running the program yourself.
-
You access the cluster through a single node, often denoted the frontend or head node (in our case hpclogin). The frontend node is identical to the other nodes, but it is set up to allow access from the Internet. Your day-to-day interaction with the cluster goes through the frontend. But, you should not run any computation or memory intensive programs on the frontend. All users share the frontend’s resources and you should only use it for basics things like looking around the file system, writing scripts, and submitting jobs.
1.5. Learning to use the shell
When interacting with the cluster you will be using a shell on a Linux/UNIX system. If you are not familiar with these concepts we recommend the Shell novice tutorial from Software Carpentry
2. Connecting to the cluster
Below you can find a few basic steps, to get you setup and ready to connect to IITJ HPC.
2.1. Terminal
If you are on a UNIX system (i.e. either Linux or Mac OS), a terminal will already be present natively in your operating system. If you are on Windows, then we recommend you install Putty or MobaXTerm which is a very good UNIX emulator, and includes already useful things like an X server and a package management system to help you use languages like Python or Perl.
2.2. Connect to the cluster
When you receive confirmation, that your account has been activated, you can then connect to the cluster by opening a terminal and using:
ssh user-name@hpclogin.iitj.ac.in If you need to display any graphics, you can use instead
ssh -X user-name@hpclogin.iitj.ac.in And a session on the terminal will be opened, within the login node of the cluster.
3. Running Jobs on the HPC
Since IITJ HPC is a shared system, all computations must be carried out through a queue. Users submit jobs to the queue and the jobs then run when it’s their turn. To handle different workloads, jobs can be submitted to one or more partitions, which are essentially queues that have been assigned certain restrictions such as the maximum running time.
The queueing system used at IITJ is Slurm. Users that are familiar with Sun Grid Engine (SGE) or Portable Batch System (PBS), will find Slurm very familiar.
Note : A node can be shared by multiple users, so you should always take extra care in requesting to correct amount of resources (nodes, cores and memory). There is no reason to occupy an entire node if you are only using a single core and a few gigabytes of memory. Always make sure to use the resources on the requested nodes efficiently. To get an overview of the available partitions:
[myuser@headnode1]$ sinfo
This will list each partition and all of the compute nodes assigned to each partition and the maximum walltime (running time) a job in the partition can have. By typing a slightly different command:
[myuser@headnode1]$ sinfo -N --long
All nodes will be listed and all partitions they belong to, together with the available resources such as the number of cores per node, available memory per node. The queueing system allows us to submit an batch job. In the following sections we the method.
3.1. Batch jobs
Batch jobs are best suited for computations lasting longer or resource demanding analyses. Batch jobs are submitted to the queue like interactive jobs, but they don’t give you a shell to run commands. Instead, you must write a job script which contains the commands that needs to be run.
A job script looks like this:
#!/bin/bash
#SBATCH --partition small
#SBATCH -D /my/working/directory
#SBATCH -c 1
#SBATCH --mem 4G
#SBATCH -t 02:00:00
echo hello world > result.txt
The lines beginning with #SBATCH communicate to Slurm which parameters we want to set for a specific task, or what kind of resources we want to be reserved for that particular analysis. The job script specifies which resources are needed as well as the commands to be run. Line 2 specifies that this job should be submitted to the partition. Line 3 tells the scheduler that on execution should go (or chdir) to a specific folder where we want the analysis to be performed. Line 4 specifies that we want a single core to run on, and line 5 specifies that we want 4G of memory per allocated core. Finally, line 5 indicates we are reserving 2 hours to execute this script. Warning At the moment (issue under investigation) all three of –mem, -t and -D need to be specified in the job script, to make sure the job is scheduled in the correct way and your work is distributed as much as possible across all available resources.
See the table below for an overview of commonly used resource flags:
| Short Flag | Long Flag | Description |
|---|---|---|
| -A | -account | Account to submit the job under. |
| -p | -partition | One or more comma-separated partitions that the job may run on. |
| -c | -cpus-per-task | Number of cores allocated for the job. All cores will be on the same node. |
| -n | -ntasks | Number of cores allocated for the job. Cores may be allocated on different nodes. |
| -N | -nodes | Number of nodes allocated for the job. Can be combined with -n and -c. |
| -t | -time | Maximum time the job will be allowed to run. |
| -mem | Memory limit per compute node for the job. Do not use with mem-per-cpu flag. | |
| -mem-per-cpu | Memory allocated per allocated CPU core. |
The rest of the script is a normal Bash script which contains the commands that should be executed, when the job is started by Slurm. To submit a job for this script, save it to a file (e.g. example.sh) and run:
[myuser@headnode1]$ sbatch example.sh
Submitted batch job 17129500
[myuser@headnode1]$
3.2. Checking job status
To check the status of a job:
[myuser@headnode1]$ squeue -j 17129500
To check the status of all of your submitted jobs:
[myuser@headnode1]$ squeue -u USERNAME
You can also omit the username flag to get an overview of all jobs that have been submitted to the queue:
[myuser@headnode1]$ squeue
3.3. Cancelling a job
Jobs can be cancelled using the scancel command:
[myuser@headnode1]$ scancel 17129500
4. Applications
Several programs with different versions are available on HPC systems. Having all the versions at the disposal of the user simultaneously leads to library conflicts and clashes. In any production environment only the needed packages should be included in the environment of the user. In-order to use python3.7 the appropriate module should be loaded.
$module load python/3.7
Modules are “configuration” set/change/remove environment variables from the current environment. Useful module commands
- module avail: display the available packages that can be loaded
- module list: lists the loaded packages
- module load foo: to load the package foo
- module rm foo: to unload the package foo
- module purge: to unload all the loaded packages
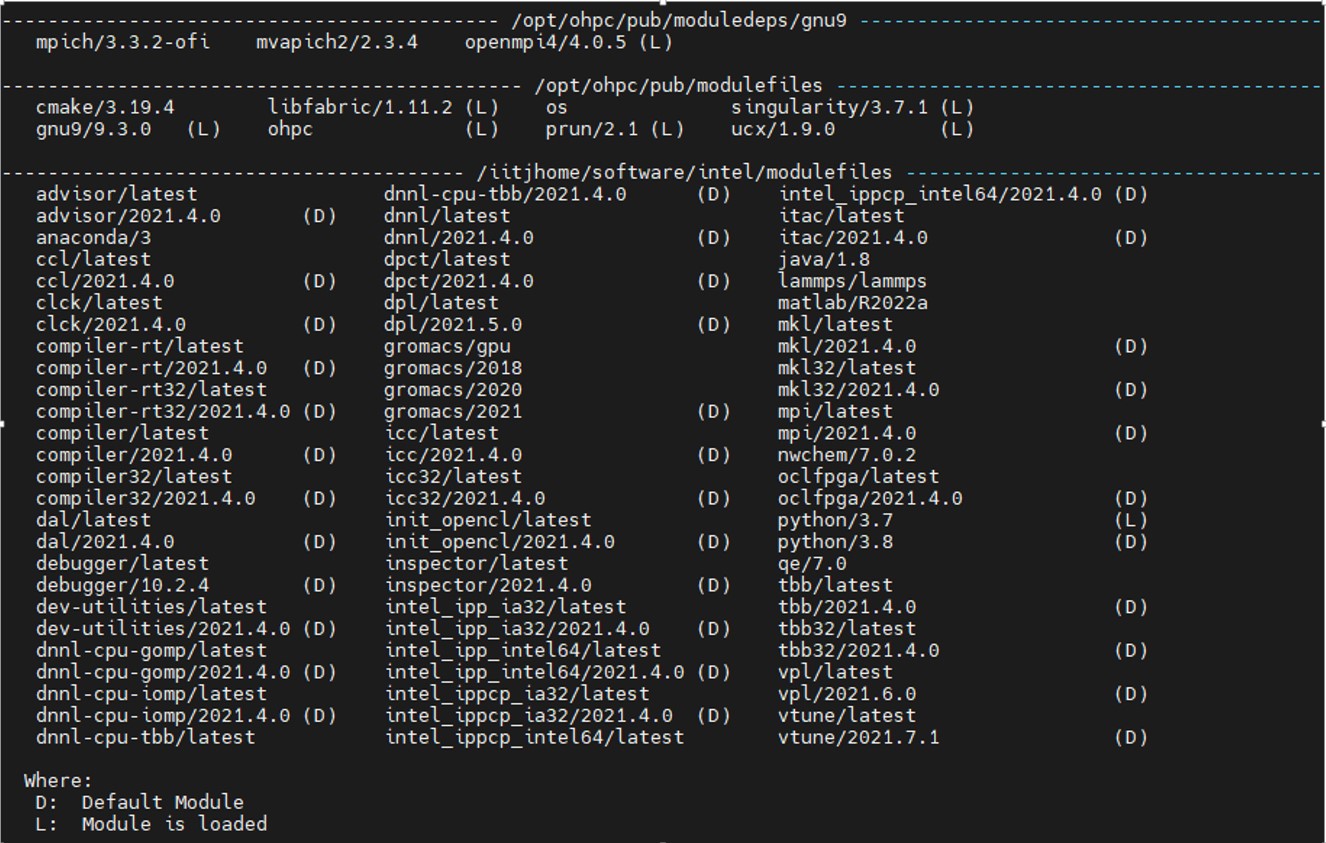
List of available Modules is below:-
For detailed information on the usage of module check the man pages
$ man module